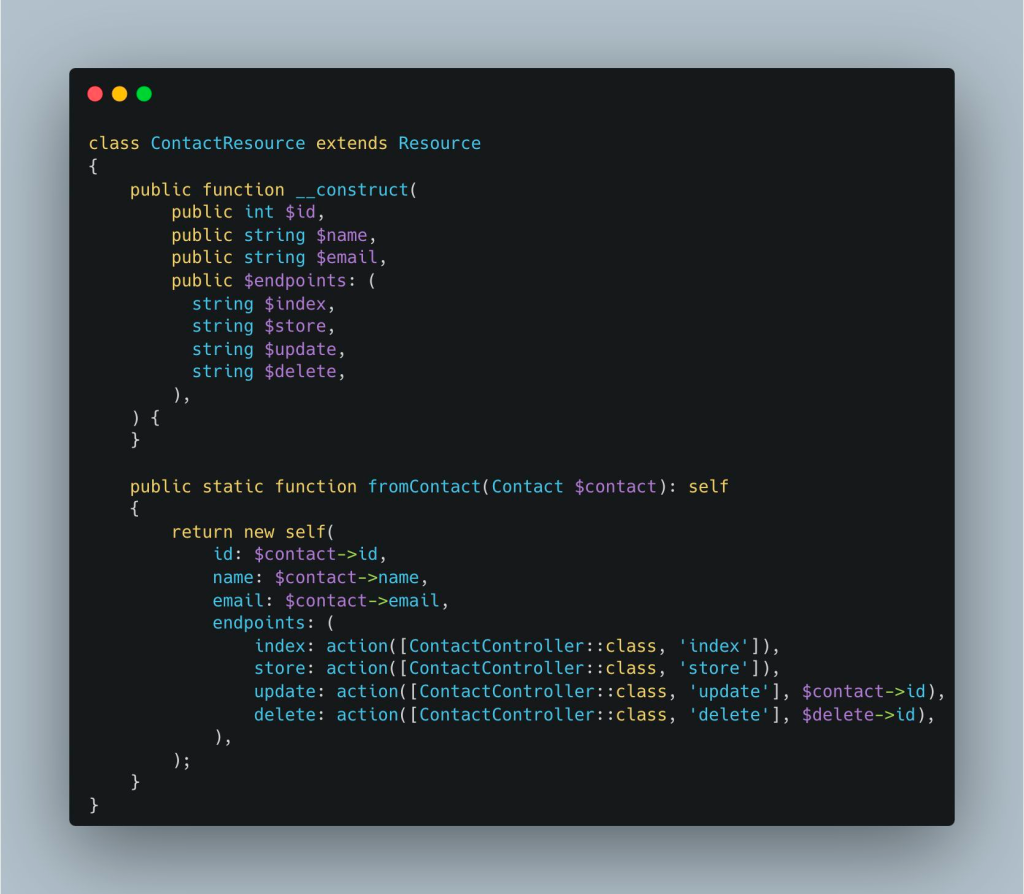
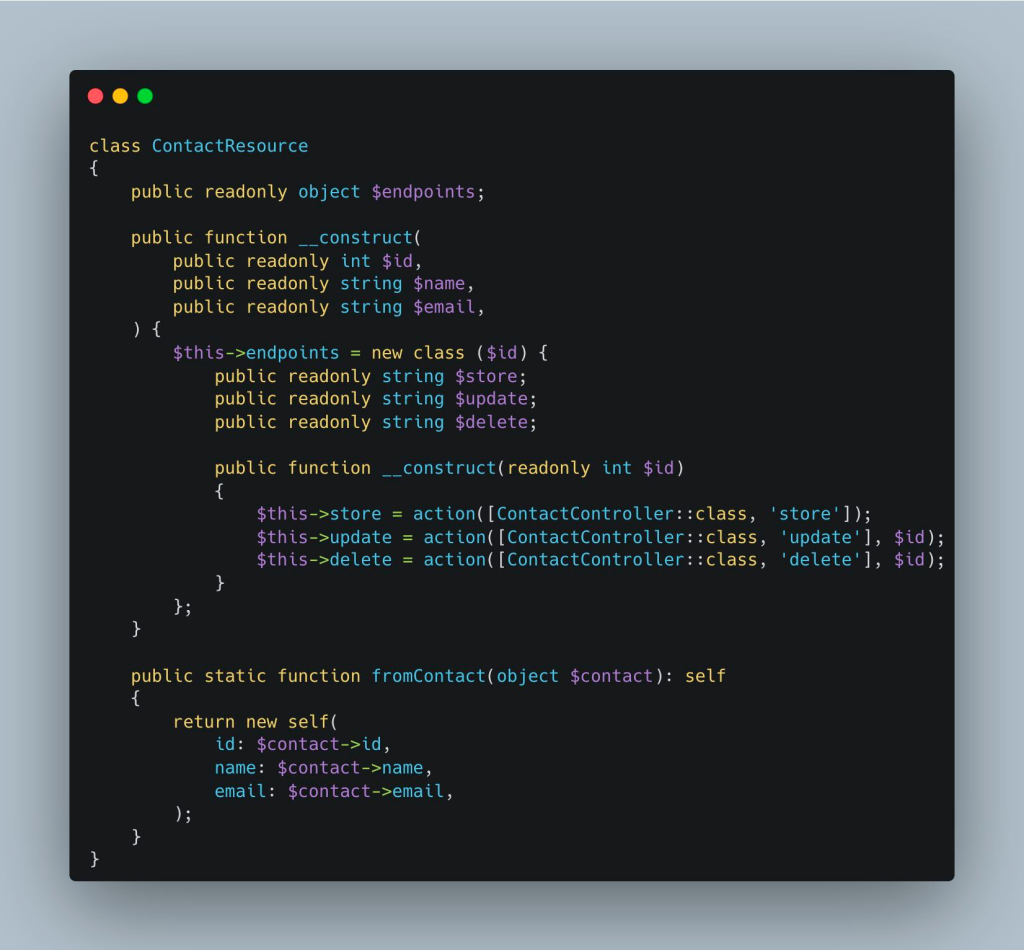
There is a hard truth in SaaS: You can outsource your infrastructure, your payments, and your CRM, but you cannot outsource your responsibility.
Nothing is more frustrating for an engineering team than dropping everything to patch a bug caused by an upstream vendor. It feels like cleaning up a mess you didn’t make.
It’s even worse when shared customers are affected. It is incredibly tempting to say, “It’s not us, it’s [Vendor Name].”
But to the customer? That sounds like an excuse.
If they pay us, the “whole product” experience is on us. If a vendor breaks, it means our resilience strategy failed, or our vendor selection process needs review.
The perception of fault is a reality of ownership. We take the heat so the customer doesn’t have to navigate the complexity of the supply chain.