Infrastructure layer: persistence, data transfer, low-level operations.
And there’s an implicit order of dependencies: higher layers should depend on classes/functions from lower layers. If a lower layer needs to communicate with a higher layer, it should do so through events.
This has greatly helped me understand and design highly decoupled, cohesive, applications.
I do find event-driven architectures to be the pinnacle of resilience and fail-tolerance in software. In fact, that’s pretty much how the real world works: for every action, there’s a reaction.
In synchronous communication, we have an orchestration of interactions between services. The orchestrator needs to know every single service and the order it should be called. High coupling: consumers and producers of information need to constantly know each other. Adding or removing services, or upgrade their interfaces are hard so the owning teams need constantly syncs with each other to know what breaking changes need to be prepared for. It guarantees data is updated after the action is executed.
In asynchronous communication, we have a choreography of services reacting to each other’s events. There’s no orchestrator, no single point of failure (theoretically; realistically there’s the event broker). Adding or removing services can be done at any time, without disrupting other services. Data will eventually be consistent, but there’s no guarantee when exactly that’ll be.
And here’s the kicker: complex systems will most probably use a mix of both. And it’s very healthy that that happens. We have processes that can be eventually consistent, and asynchronous, but there are other systems that need to do things now and need to do it well, or everything must fail. And even in success there needs to be idempotency guarantees.
When implementing a queueing system, it’s easy to forget that the async benefits only apply after the jobs are dispatched to the queues. The dispatching, itself, is almost always a sync process. If that fails, our systems might return errors to the users. And there are other ways of producing errors besides bugs in the code.
This was a lesson recently learned the hard way. When everything’s working well, we tend to almost forget we have this additional infrastructure that supports some workloads that we don’t want to – and probably don’t need to – make our users wait to be fully executed. When we implement a queueing system we subconsciously assume that the two planes of operation (sync and async; the request and the processing of that request, respectively) are fully independent and that exceptions and problems in one don’t affect the other.
And, to some extent, we’re right!
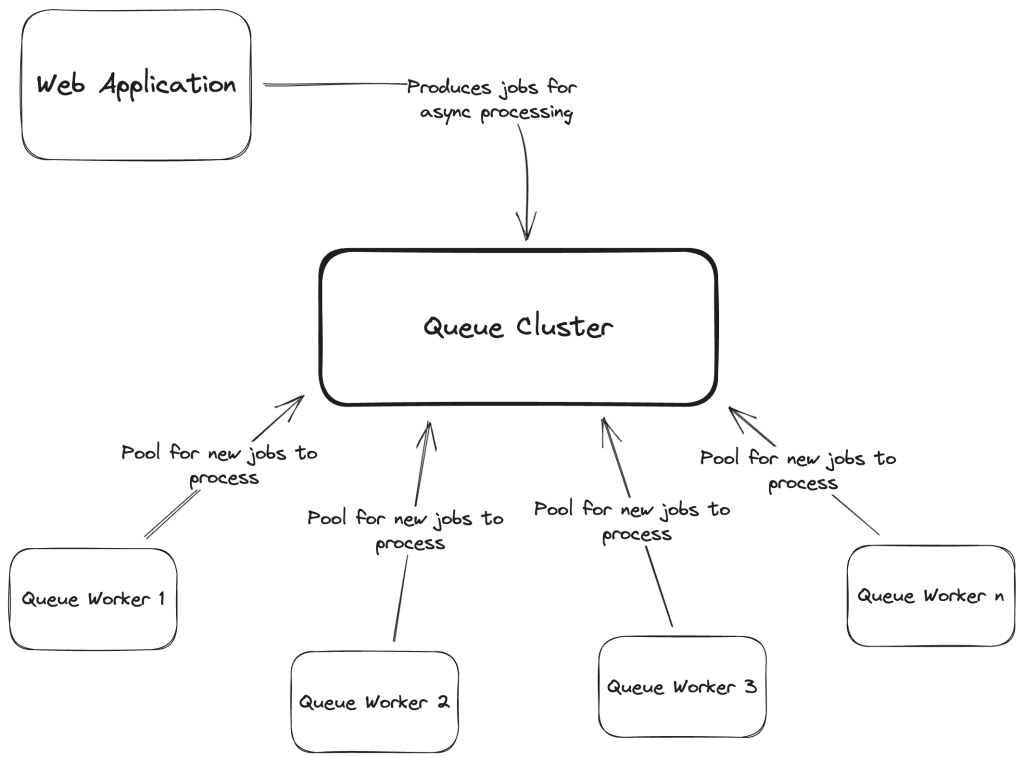
A basic queue system design
If we research how to implement a queue system, we’ll get to an architecture something like the following:
Fig1. A basic queueing system architecture diagram
Don’t delve too much into its simplicity as it was on purpose. But it does capture what we might describe as a valid queueing system: we have our Web Application producing (or queueing) jobs in our Queue Cluster, and then Queue Workers (long-lived processes) will continuously pool for new jobs, reserve and process them.
Nothing exotic; nothing magically complex. So what’s this blog post about?
How a queue system quickly becomes a single point of failure
We can’t blindly consider a queueing system as something secondary, unimportant, and not critical to our system’s architecture. Here’s what I mean: if we look at Fig. 1, above, we can say that everything north of the Queue Cluster is a synchronous flow and everything south of it is asynchronous. We tend to instinctively assume a queueing system is totally asynchronous and fail-tolerant but that will lead to possible headaches and unavailability of part of our system.
You see, the synchronous part can still fail for any number of reasons, and when that happens we’ll probably lose the job that should have been dispatched to the queue unless we take proactive actions.
If we look closely at the aforementioned architecture, we can note a few problems:
The dispatching of the jobs relies on the operation being 100% correct all the time and no problem occurs between services’ communication (between the Web Application and the Queue Cluster).
Relying on a single cluster to persist data from (possibly) multiple application domains/services.
If any of those problems happen, we’ll probably lose any reference to the jobs that aren’t dispatched to the queue, and we won’t have a way to retry that operation.
How to improve resilience and have a fail-tolerant dispatching logic
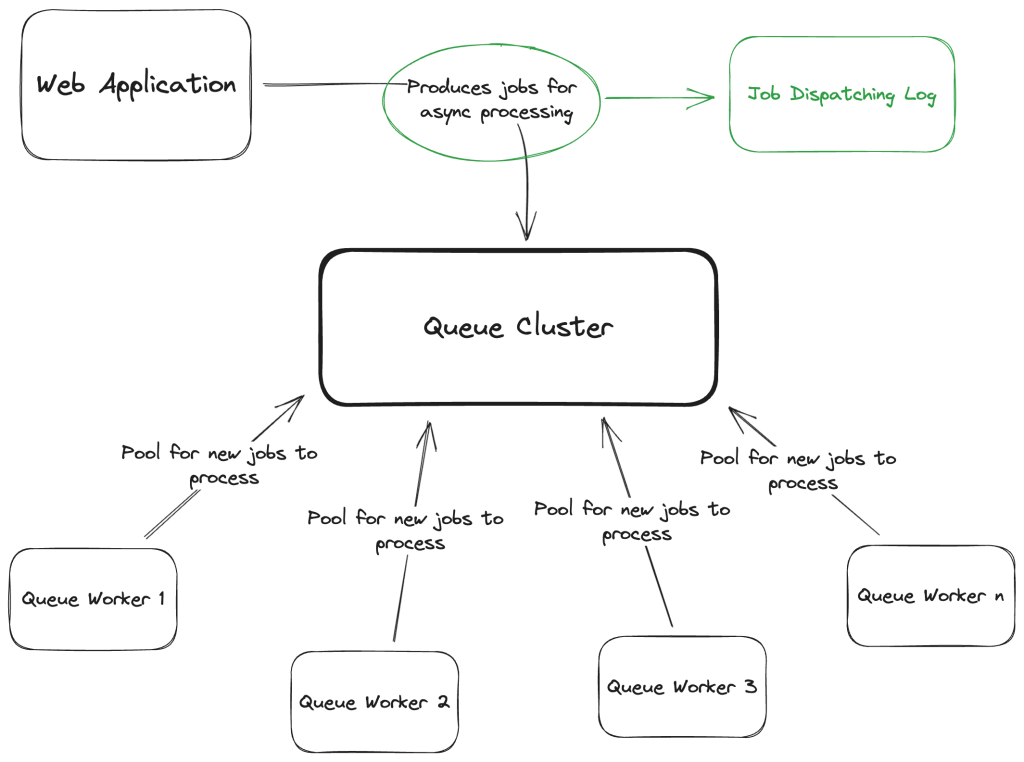
So, what to do to prevent the first issue, above, and handle failures gracefully with the option to eventually retry them when the error is fixed? Well, here’s a possible solution to guarantee that:
Fig. 2 – Adding an log for dispatching jobs
We can introduce a transactional outbox pattern. What this means, putting it simply is that a copy of the job is saved in a log before the dispatch itself.
This, in fact, will allow us to re-dispatch jobs for whatever reason. If retrying failed dispatching jobs is all we need, we can remove this record after the dispatch is successfully done or simply only write to this log on dispatch failures. The Queue Cluster can be unavailable for whatever time necessary, and once it comes back online, all jobs’ dispatching can be retried.
Now, to the next problem.
Minimise a domain’s cluster-specific problems’ impact on other domains
With the dispatching failures being gracefully handled, we can turn to the problem of depending on a single Cluster. If it goes down – for maintenance or because it’s filled up, to name a few possibilities- it’ll take the entire async part of our architecture down, impacting all the consumers of that Cluster.
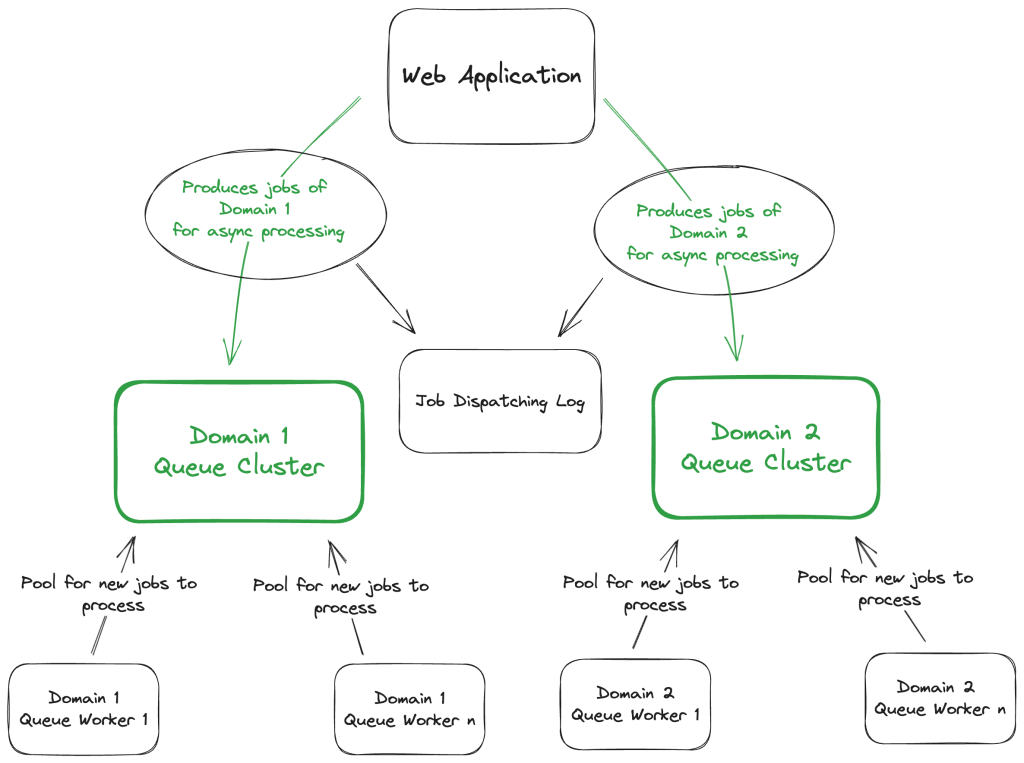
A possible solution for guaranteeing that the blast radius of the unavailability of a Cluster doesn’t propagate to all domains/services is as follows:
Fig. 3 – Multiple Queue Clusters per domain/service
Introducing a Queue Cluster per domain/service, each one independent from the others can limit the impact on the owning domain/service. So if one Cluster is down for any reason, the others will continue to operate normally.
This brings, of course, other consequences: increased infrastructure to manage and increased costs. As with everything in life, use this wisely and in the correct measure to the criticality of your architecture.
In conclusion
This is a cautionary tale. I was recently reminded the hard way that having a queueing system doesn’t magically detach itself from the application it belongs to and can, actually, bring it to its knees. Addin redundancy and some fallback strategies to prevent it from losing data when things aren’t working as expected.
At least, now, we learned a few to make queues more resilient, robust, and trustworthy.
At Infraspeak, the entire engineering team gets a couple of days, every month, to fully dedicate to pet projects. As me and my friend Nelson were working on our automations Bot, we were introducing the first Entities to our domains without noticing, at first, that we were creating invalid instances. This article shows why those instances were broken from the start, and how to ensure we always work with valid instances even before persisting them in a data store.
Entities are defined by a thread of continuity and identity. This means that due to having a unique ID, whenever their properties’ values change, it’ll still be the same Entity and we’ll always be able to reference to it (that’s the continuity part).
When developing software, it’s broadly accepted that we should strive for immutable objects. If we want to change something inside immutable objects, we make new instances with the updated values. This prevents that during execution of the application logic, an object gets unintentionally mutated, probably putting it in an invalid state. I won’t delve to much into this pattern (rain check for another post), but the point is that when working with immutable objects, they should be in a valid and usable state. Anywhere that accepts that object doesn’t need to worry about constantly check for its validity.
So, if having an identity, via a unique ID, completely defines an Entity, and it should be considered immediately valid upon instantiation, then using sequentially-generated number from a data store as the source of the Entity identity is a problem. And here’s why: we can’t safely predict what the next number is, and it’s not even the Entity responsibility to do so, leaving us in a dilemma: we need to instantiate an Entity to persist it, and get that ID, but we can’t because to instantiate it we need to have an ID. So, what to do?
A naive, instinctive, workaround would be to accept two types for the ID property: an integer or a null. This does fix the problem of instantiating the object but doesn’t make it valid, and we implicitly created a dependency on the data store, now, because we need to persist the entity first, and create a new instance with the actual ID, before we can use it further in the application.
The thing is, although clearly broken, this is the most common implementation that I’ve seen when working with Entities. I, too, have done it this way, but I’ve recently found another way of working with totally valid Entities without requiring them to be persisted to the data store before being used in the application.
The trick is to drop the use of internally-generated sequential IDs that come from the data store, at application level, and replace them with randomly, uniquely-identifiable IDs, like UUIDs. By using UUIDS, we can both generate unique IDs and have fully valid Entity instances to work with immediately, and remove a hard dependency on the data store for that purpose.
We can even save on object instantiation times, since we no longer need to re-create an Entity class upon persistence because there’s probably no new properties to fetch, where before we would need to do it to have the ID populated from the data store. Persistence of the Entity becomes an implementation detail.
A few weeks ago, during a mentoring session that I hosted with a few colleagues from work, we ended up talking about good examples of using the Singleton Pattern in software development. As we discussed, it appeared that this pattern was in the “no-no” box, for some reason, and labeled as an anti-pattern. I think, however, that there are very good use cases for using it. This article shows how to leverage the Singleton pattern to optimize resources and prevent our applications from holding unnecessary class instances in memory.
The Singleton pattern is a creational design pattern with the purpose of enforcing the use of the same instance of a class in the application. It means that the investment of creating an instance of a class with this pattern is only paid once, making subsequent calls to methods of the same class faster. However, this means that that instance also shares any and all state, which makes it tricky to use in cases where the different calls to the class needs to have independent state management. That’s why, generally speaking, that using this design pattern is not taken into much consideration. Which is a shame, because I think it’s perfect to create and manage instances of service classes.
Service classes, also known as Managers or Handlers, are a set of classes that host behaviour methods. This definition is a little vague, on purpose, since the actual type of behaviour they’ll contain depends on which software layer it’s on (application, domain, infrastructure). Nevertheless, the key point is that they should be stateless, so instantiating several instances of the same service class is unnecessary and redundant. But that’s what I generally see happening when using Dependency Injection of service classes.
Creating instances of objects takes computational resources (mainly, memory), and they’ll live in-memory for as long as a request is being handled, before being garbage-collected or explicitly removed. If we have many uses of the same service class, instantiating it several times is a waste of resources and makes the process take more time to be handled than necessary, which is not very performant either.
That’s when I find that using the Singleton pattern shines, because after the first instantiation of the service class, the same instance will be used, instead of continuously creating new instances.
Every week I join Daniel Maciel to share tips and suggestions for developers.
In this episode, we talk about Design Patterns as generalist solutions to solve recurring problems in software development. It is important that programmers know and learn about these patterns and knows how to research and analyze the need for their implementation in a project.
Every week I join Daniel Maciel to share tips and suggestions for developers.
In this episode we talk about the activity of reviewing code to ensure its quality, also known as: “Code Review”. When should we do it? What are the main concerns and how should we start?
Last May 29th, 2021, my very first talk was played live, via YouTube, as part of the Speaking About Web & Mobile Development conference, the biggest event related to software development in Beira Baixa, bringing together communities of meet-ups and events, speakers, companies and sponsors in one place, promoting the national ecosystem.
It’s a very special occasion for me, because it’s my very first participation as a speaker in a conference! In this talk I shared a lot of actionable advice on how to configure a local Docker setup that enables developers to work on as many projects as they need in a simple and practical way.
Every week I join Daniel Maciel to share tips and suggestions for developers.
In this episode we talk about refactor. When should we refactoring the code and what can we do to minimize problems in this process? These are some of the issues that are addressed.