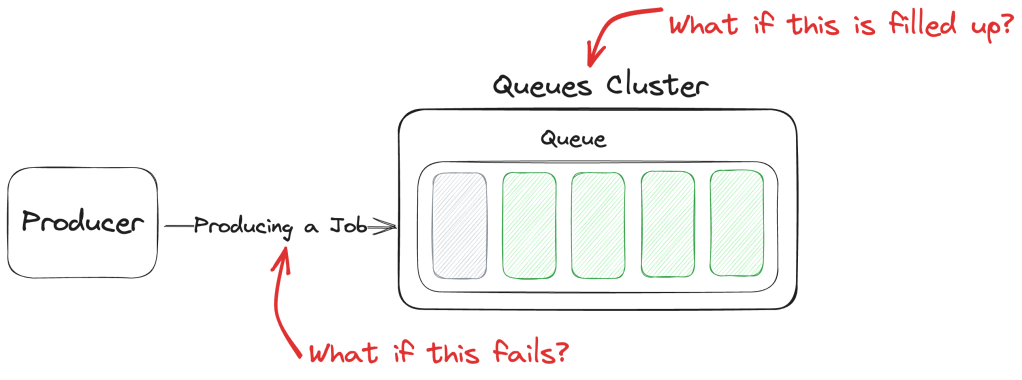
When implementing a queueing system, it’s easy to forget that the async benefits only apply after the jobs are dispatched to the queues. The dispatching, itself, is almost always a sync process. If that fails, our systems might return errors to the users. And there are other ways of producing errors besides bugs in the code.
This was a lesson recently learned the hard way. When everything’s working well, we tend to almost forget we have this additional infrastructure that supports some workloads that we don’t want to – and probably don’t need to – make our users wait to be fully executed. When we implement a queueing system we subconsciously assume that the two planes of operation (sync and async; the request and the processing of that request, respectively) are fully independent and that exceptions and problems in one don’t affect the other.
And, to some extent, we’re right!
A basic queue system design
If we research how to implement a queue system, we’ll get to an architecture something like the following:
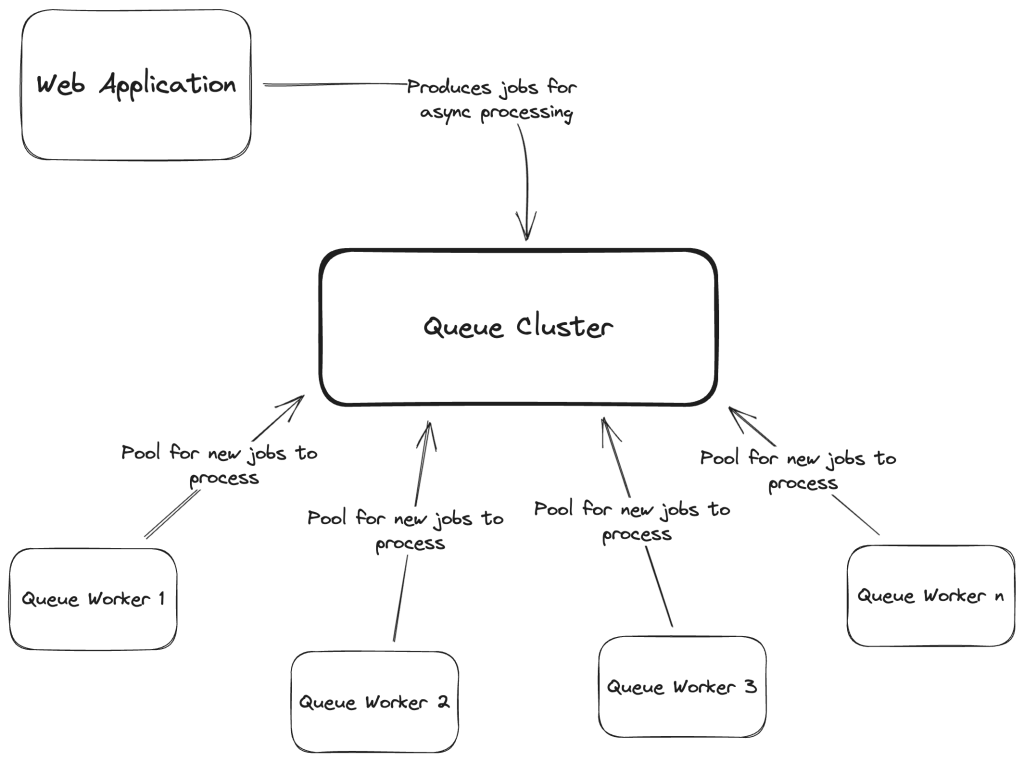
Don’t delve too much into its simplicity as it was on purpose. But it does capture what we might describe as a valid queueing system: we have our Web Application producing (or queueing) jobs in our Queue Cluster, and then Queue Workers (long-lived processes) will continuously pool for new jobs, reserve and process them.
Nothing exotic; nothing magically complex. So what’s this blog post about?
How a queue system quickly becomes a single point of failure
We can’t blindly consider a queueing system as something secondary, unimportant, and not critical to our system’s architecture. Here’s what I mean: if we look at Fig. 1, above, we can say that everything north of the Queue Cluster is a synchronous flow and everything south of it is asynchronous. We tend to instinctively assume a queueing system is totally asynchronous and fail-tolerant but that will lead to possible headaches and unavailability of part of our system.
You see, the synchronous part can still fail for any number of reasons, and when that happens we’ll probably lose the job that should have been dispatched to the queue unless we take proactive actions.
If we look closely at the aforementioned architecture, we can note a few problems:
- The dispatching of the jobs relies on the operation being 100% correct all the time and no problem occurs between services’ communication (between the Web Application and the Queue Cluster).
- Relying on a single cluster to persist data from (possibly) multiple application domains/services.
If any of those problems happen, we’ll probably lose any reference to the jobs that aren’t dispatched to the queue, and we won’t have a way to retry that operation.
How to improve resilience and have a fail-tolerant dispatching logic
So, what to do to prevent the first issue, above, and handle failures gracefully with the option to eventually retry them when the error is fixed? Well, here’s a possible solution to guarantee that:
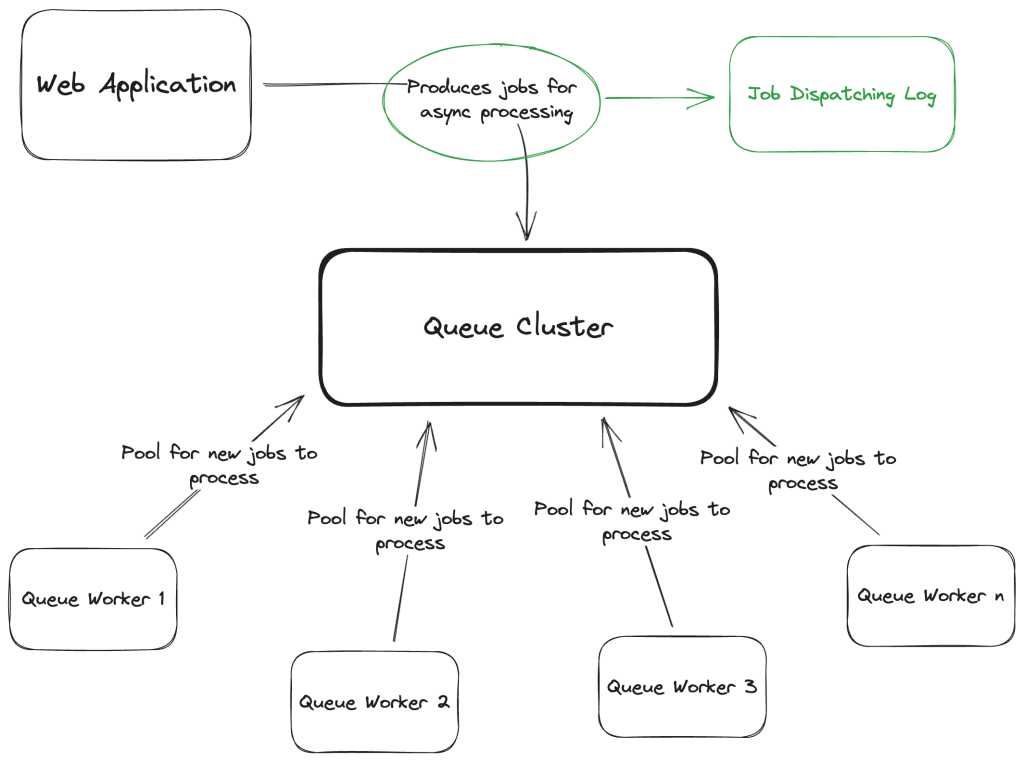
We can introduce a transactional outbox pattern. What this means, putting it simply is that a copy of the job is saved in a log before the dispatch itself.
This, in fact, will allow us to re-dispatch jobs for whatever reason. If retrying failed dispatching jobs is all we need, we can remove this record after the dispatch is successfully done or simply only write to this log on dispatch failures. The Queue Cluster can be unavailable for whatever time necessary, and once it comes back online, all jobs’ dispatching can be retried.
Now, to the next problem.
Minimise a domain’s cluster-specific problems’ impact on other domains
With the dispatching failures being gracefully handled, we can turn to the problem of depending on a single Cluster. If it goes down – for maintenance or because it’s filled up, to name a few possibilities- it’ll take the entire async part of our architecture down, impacting all the consumers of that Cluster.
A possible solution for guaranteeing that the blast radius of the unavailability of a Cluster doesn’t propagate to all domains/services is as follows:
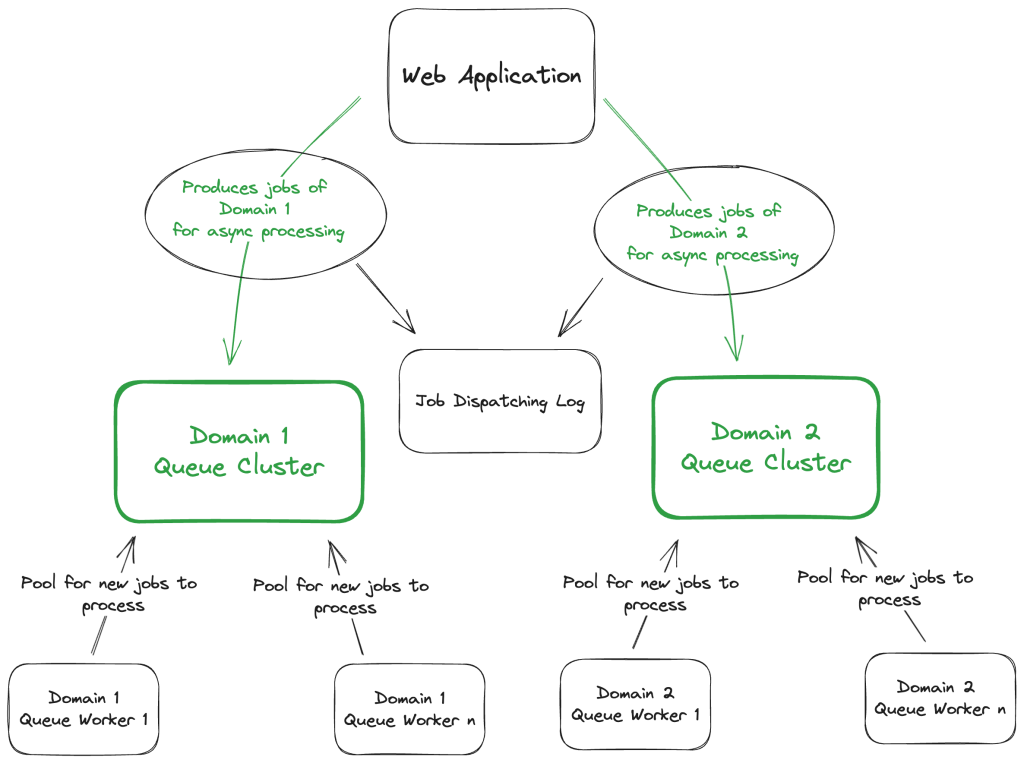
Introducing a Queue Cluster per domain/service, each one independent from the others can limit the impact on the owning domain/service. So if one Cluster is down for any reason, the others will continue to operate normally.
This brings, of course, other consequences: increased infrastructure to manage and increased costs. As with everything in life, use this wisely and in the correct measure to the criticality of your architecture.
In conclusion
This is a cautionary tale. I was recently reminded the hard way that having a queueing system doesn’t magically detach itself from the application it belongs to and can, actually, bring it to its knees. Addin redundancy and some fallback strategies to prevent it from losing data when things aren’t working as expected.
At least, now, we learned a few to make queues more resilient, robust, and trustworthy.
